| 语义模型 | <返回 |
|


|
|
概述
语义模型,负责把面向技术的数据组织成面向业务的数据,以供业务人员查询分析使用。,该功能点提供"左树右表+卡片"的界面展示方式,左侧展示"语义模型分类"树,右侧以列表形式展示"语义模型编码、语义模型名称、数据源"等报语义模型信息。双击列表中的语义模型,进入语义模型"卡片"界面,展示语义模型的详细基本信息。 语义模型的内部结构 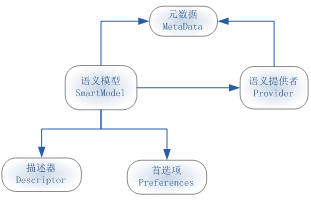
语义模型主要由以下几部分构成:
|
操作指引
 |
|
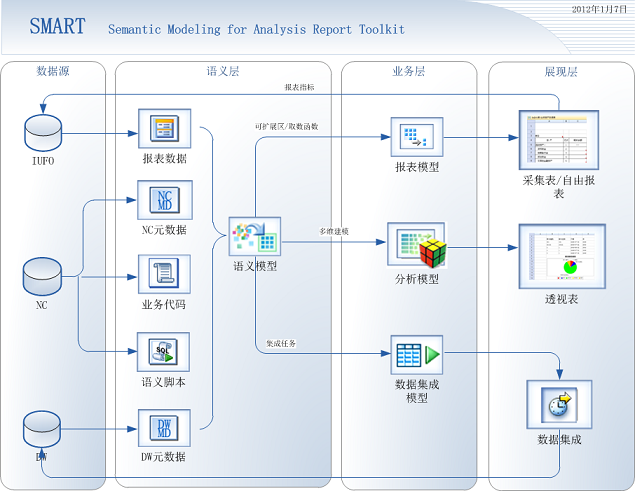
语义查询模型,语义层的建模工具,将应用在三个方面: 业务报表: 语义模型作为报表的取数接口,通过iUFO的可扩展区域、取数函数等形式,将语义模型应用到自由报表和采集表。 分析报表: 语义模型作为事实表或维度表,构建在OLAP模型中,应用到透视表或透视图。 数据集成: 语义模型作为数据集成的主要数据输入接口,提供数据集成的原始数据,进行ETL操作。 语义模型的执行流程如下图所示: 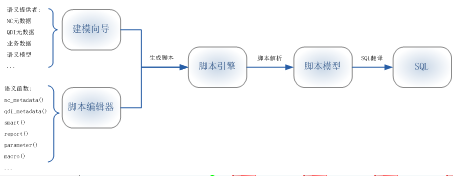
语义模型执行过程可分为以下步骤: 第一步:语义模型脚本化 语义模型中的对象结构将转变为字符串形式的语义脚本。 第二步:脚本对象化 通过脚本引擎把语义脚本解析为脚本模型,即把字符串形式的脚本 对象化。 第三步:脚本模型翻译为SQL 基于脚本模型,处理其中的语义函数,把脚本模型翻译为标准SQL语句。 运行态描述器会在这一步被处理。 第四步:执行sql,把结果集封装为DataSet,返回DataSet。 由于运行态描述器的存在,每次执行语义模型时获取的最终sql都是不同的,但是,语义模型本身对应的脚本模型是相同的。基于性能考虑,我们可以把语义模型对应的脚本模型缓存起来。这样一来,只有第一次执行语义模型时,我们需要完整执行上述四个步骤,接下来的每次执行,我们只需取得该缓存的脚本模型,再做第三、四步的处理即可。 |
|
关键应用
|
||||||||||
|
||||||||||
|
 |
注意 | |||
|
||||

|
常见问题 | |||
|
||||